Under början av detta år har jag hittills haft cirka 40 möten, en stor andel av dessa har varit med olika varumärken där den största frågan har varit: "Hur skalar man på Meta under 2026?"
Det finns många saker man kan göra för att förstå det. Men den absolut viktigaste saken att förstå är hur Metas algoritm rangordnar och prioriterar innehåll.
Jag har jobbat med Performance Marketing i 7 år, och en stor nyckel för mig har varit att alltid vara uppdaterad med att förstå Metas algoritmer och modeller på djupet.
När du förstår någonting på djupet kan du rita en strategi som är gångbar och framgångsrik utifrån förutsättningarna på plattformen.
Den 28 januari 2026 meddelade Meta att man fördubblade antalet GPUs som används för att träna deras senaste rankningsmodell: Generative Ads Recommendation Model (GEM).
GEM är Metas stora “hjärnmodell” för annonsrekommendationer. Den lär sig mönster från enorma mängder data om hur människor engagerar sig med innehåll och annonser, och använder den kunskapen för att förbättra hur Meta rankar och matchar annonser till rätt person i rätt ögonblick.
Med andra ord är det otroligt viktigt för annonsörer, medieköpare och marknadschefer att förstå hur GEM påverkar leverans och kreativa beslut.
Vad ligger till grund för GEM?

1. Modellen är tränad på både annonser och organiskt innehåll, för att på ett djupare plan förstå vad användare bryr sig om, inte bara på last click signaler.
2. Modellen har två stora "feature families" som modelleras annorlunda:
a) Sekvensdata: användarens beteende över tid, i ordning. T.ex vilka Stories eller Reels du har tittat på, vilka annonser du pausat, sparat etc. Fokuserar på mönster över tid.
b) Icke-sekvensdata: Statistiska egenskaper som inte är en tidsserie. Beskrivande fakta om användaren, innehåll och sammanhanget vid ett givet tillfälle.
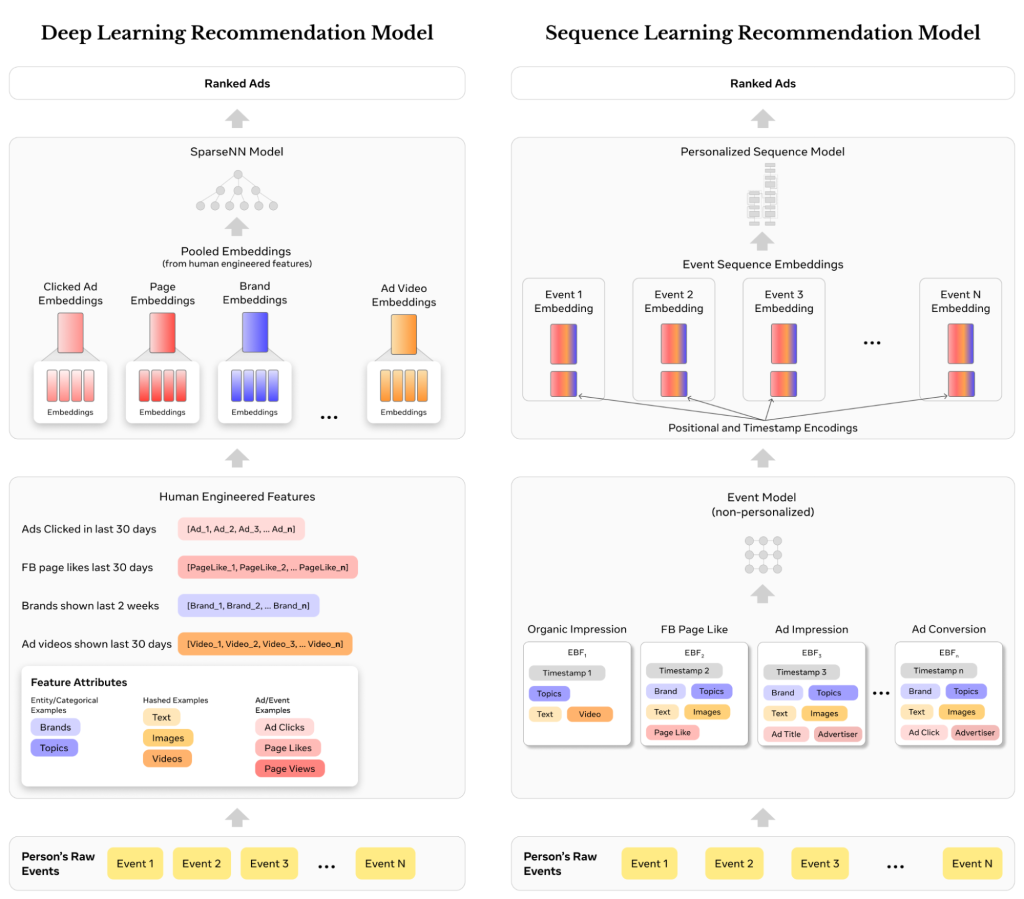
GEM använder sig av båda feature families för att förstå var en användare är just nu i sin resa med hjälp av sekvensdatan och icke-sekvensdata för att förstå vad annonsen är samt i vilket sammanhang den visas.
Målet är att förstå om annonsen passar användaren just nu.
GEM används som en stor central modell som kan lära sig breda mönster från enorma mängder data. Eftersom modellen är för tung för att köras överallt används den sedan som en lärare som för över kunskap till många mindre vertikala modeller som faktiskt körs i produktion.
Det är dessa mindre, vertikala modeller, som på millisekunder räknar ut prediktioner för dina annonser, som sedan vägs ihop med auktionen och bestämmer vad som ska visas och när.
Hur optimerar man efter GEM i sin annonsering?
Kan man då direkt optimera för GEM? Svaret är nej.
Men det du kan göra är att skapa innehåll på ett sätt som gör att modellerna med större sannolikhet kan matcha dina annonser till rätt personer vid rätt tillfälle.
Hur gör man detta?
1. Skapa användarresor, inte enskilda annonser (sekvensinlärning)
Eftersom GEM modellerar långa beteendesekvenser, är den motiverad till att servera annonser som är rimliga inom kontexten av en användares beteende.
Detta kan du som annonsör utnyttja genom att skapa innehåll som stödjer olika "state of minds".
- Problem aware (Varför du känner "X")
- Solution aware (Här är vad som löser "X")
- Product aware (Varför denna produkt nu?)
- Offer/decision (Erbjudande/garanti/price anchor/proof)
Sedan behöver du skapa annonser i serier, det vill säga skapa en serie av annonser som följer en logisk ordning, som adderar information istället för att repetera samma hook.
2. Frontloada i ditt innehåll (mycket information snabbt)
Modellen måste snabbt förstå vad annonsen är, eftersom annonsens attribut är en central input i icke-sekvensdelen, och därför gynnas du när ditt innehåll gör det lätt att kodas tydligt, detta gör du genom att i ditt innehåll besvara:
- Vad är produkten eller tjänsten?
- Vilken kategori/use case har produkten eller tjänsten?
- Vem är produkten eller tjänsten för?
Om din öppning är vag får modellen en svagare signal om vad innehållet är och står för, vilket gör matchningen till rätt målgrupp svår.
Detta betyder inte att du ska visa en packshot på din produkt med en CTA-knapp som tar upp 75% av första bildrutan, men snarare att ge tydlighet i vem innehållet är för, vilket problem/önskan samt vad för typ av lösning det är.
3. Mata modellen med ett “kreativt ordförråd”
Eftersom GEM agerar som en lärare som generaliserar mönster och för vidare lärdomarna till vertikala modeller, gynnas du av att ha diversifierat men strukturerat innehåll.
Detta betyder inte att du ska “go crazy” och skapa massor av typer av olika innehåll, det behövs en plan.
För att göra detta behöver du bygga ett system som grundas i meningsfulla skillnader:
- Hook (confession, fråga, shockerande fakta, myth-bust)
- Proof (recension, demo, expert, data/logik)
- Mekanism (hur det fungerar)
- Persona/avatar (vem är det för)
- Erbjudande (rabatt, trial, garanti)
Här är det viktigt att inte använda sig av random variationer, utan att varje iteration ska addera en ny signal till GEM.
Den slutliga domen
2026 kommer att vinnas av de som bygger ett kreativt system som gör det lätt för Metas modeller att förstå vad du säljer, för vem och när det är relevant.
I och med att Meta skalar upp beräkningskraften för GEM och använder längre beteendesekvenser och mer organisk engagemangsdata, kommer modellerna att bli ännu bättre på att välja rätt annons vid rätt tidpunkt.
Detta betyder att du som annonsör bör fokusera på följande för att vinna på Meta under 2026:
- Bygg kreativa familjer som täcker olika state of mind. Detta gör att systemet har något att matcha mot i olika användarlägen.
- Frontloada tydlighet: inte genom att visa produkten direkt, men genom att snabbt få användaren och modellen att förstå vem ditt innehåll är för.
- Iterera strukturerat: addera variationer som adderar nya signaler (hook/proof/persona/erbjudande), inte genom att skapa något annorlunda utan en plan.
Därför är mitt korta men sammanfattande svar på den initiala frågan “Hur skalar man på Meta under 2026” följande:
Bygg ett kreativt system som ger Metas modeller tydliga, konsekventa och varierade signaler, i en volym som matchar din spend, din produktekonomi och din historiska data.